دادهها به عنوان یکی از مهمترین سرمایههای سازمانها و کسب و کارها نقش مهمی را در گرفتن تصمیمات حیاتی دارند. به همین خاطر، بخشی از تمرکز و هزینههای زمانی و مالی سازمانها و شرکتها صرف جمعآوری و ذخیرهسازی و نگهداری دادههای مورد نیازشان میشود. از آنجا که روزانه حجم عظیمی از داده تولید میشوند، باید بستر مناسبی برای نگهداری و پردازش آنها فراهم کرد. «دریاچه داده» (Data Lake) یکی از انواع مخازن نگهداری داده محسوب میشود که از آن میتوان در حوزه «کلان داده» (Big Data) استفاده کرد. در این مطلب از مجله فرادرس قصد داریم به زبانی ساده به شرح دریاچه داده بپردازیم.
در ابتدای مطلب، توضیح خواهیم داد که Data Lake چیست و چه تفاوتی با سایر مخزنهای داده دارد. سپس، به ویژگیها، اهداف و مزایا و چالشهای آن اشاره خواهیم کرد و معماری آن را شرح میدهیم.
دریاچه داده چیست؟
دریاچه داده یا Data Lake مخزنی برای ذخیره کردن حجم عظیمی از داده است. این دادهها از منابع مختلفی نظیر بانکهای اطلاعاتی و پلتفرمهای SaaS جمعآوری میشوند و با هر نوع ساختاری که دارند، میتوان آنها را در دریاچه داده ذخیره کرد. دادههای استخراج شده میتوانند سه نوع ساختار داشته باشند:
- «دادههای ساختاریافته» (Structured Data): دادههایی هستند که در قالب سطر و ستون در پایگاه دادهها ذخیره میشوند.
- «دادههای غیرساختاریافته» (Unstructured Data): دادههایی نظیر متون و تصاویر، از این نوع هستند.
- «دادههای نیمه ساختاریافته» (Semi-Structured Data): فایلهایی از نوع HTML و CSS از این نوع داده محسوب می شوند.

دریاچه داده مخزنی واحد برای برای نگهداری این سه نوع داده فراهم میکند تا بتوان در هر زمان که به آنها نیاز داشتیم، به راحتی دسترسی داشته باشیم. در هنگام ذخیره کردن دادهها در دریاچه داده از شناسهها و برچسبهایی استفاده میشود تا بتوان دادهها را از طریق آنها به آسانی بازیابی کنیم. بدین ترتیب، میتوان از دو مشخصه اصلی زیر برای تعریف دریاچه داده استفاده کنیم:
- دادههای اصلی با هر نوع ساختاری که دارند، در دریاچه داده ذخیره میشوند.
- کاربران زیادی میتوانند به دریاچه داده دسترسی داشته باشند و از دادههای آن استفاده کنند.
دریاچه داده معمولاً بر روی یک سختافزار ارزان قیمت با قابلیت مقیاسپذیری پیکربندی میشود تا بتوان هر حجمی از داده را بدون نگرانی درباره ظرفیت حافظه بر روی آن ذخیره کرد. پیکربندی دریاچه داده را میتوان بر روی سختافزار موجود در سازمان یا بر روی بستر «ابر» (Cloud) انجام داد.
گهگاه اصلاح دریاچه داده با «انبار داده» (Data Warehouse) به اشتباه به جای یکدیگر به کار میروند با این که این دو مفهوم با یکدیگر متفاوت هستند و ذخیرهسازی دادهها در آنها با یکدیگر تفاوت دارند. در ادامه، به تفاوت انبار داده و دریاچه داده میپردازیم.
تفاوت انبار داده و دریاچه داده چیست؟
اهداف انبار داده و دریاچه داده از برخی جهات شبیه به هم هستند و به همین خاطر این دو مفهوم به اشتباه معادل هم در نظر گرفته میشوند:
- انبار داده و دریاچه داده مخازنی برای ذخیرهسازی دادههای سازمان است.
- انبار داده و دریاچه داده دادههای حجیمی را برای اهداف بعدی سازمان ذخیره میکنند.
با این حال، این دو نوع مخزن داده دارای تفاوتهای مهمی هستند که در ادامه به آنها میپردازیم:
- شمای خواندن و نوشتن دادهها: برای ذخیرهسازی داده در انبار داده پیش پردازشی بر روی آنها اعمال میشود تا دادهها در قالبی مشخص در انبار داده ذخیره شوند. اما در دریاچه داده، دادهها با فرمت اصلی خود ثبت میشوند و در هنگام استفاده از آنها، عملیات پیش پردازش بر روی آنها اعمال میگردد.
- پردازش دادهها: در انبار داده به منظور ذخیره دادهها، باید در ابتدا پیش پردازشهای مختلفی بر روی آنها اعمال شود که این مرحله در دریاچه داده وجود ندارد و دادهها با هر شکل و فرمتی که دارند، درون مخزن ذخیره میشوند.
- رابط کاربری: از آن جایی که در دریاچه داده انواع مختلفی داده با فرمتهای متفاوت ذخیره میشود، به منظور درک دادهها و کار با آنها باید از یک متخصص کمک بگیریم. از سوی دیگر در انبار داده، دادههای پردازش شده در قالب مشخص ذخیره میشوند و درک و کار کردن با آنها راحتتر است. بدین ترتیب، کاربران بدون دانش فنی و تخصصی با انبار داده به راحتی کار میکنند.
- انعطافپذیری: با توجه به این که برای ذخیره کردن دادهها در انبار داده از شمای خاصی استفاده میشود، به منظور اعمال تغییرات آتی بر روی آنها با چالشهایی روبهرو هستیم. دریاچه داده را در مقایسه با انبار داده به راحتی میتوان بر اساس نیاز تغییر داد.
- کیفیت دادهها: از انبار داده و دریاچه داده به منظور تحلیل و بررسی دادهها استفاده میشود. اما از آنجایی که دادهها در انبار داده با فرمت خاصی ذخیره میشوند، باید برای پیش پردازش و ذخیره آنها و اطمینان از ساختار و کیفیت دادهها، استانداردهایی را در هنگام ذخیرهسازی داده مد نظر قرار دهیم. از طرف دیگر، دادههای خام دریاچه داده برای «یادگیری ماشین» (Machine Learning) و تحلیلهای سریع مناسب هستند و برای ذخیره آنها در دریاچه داده از استانداردها و قوانین سختگیرانهای استفاده نمیشود.
- کاربران: دانشمندان داده از دریاچه داده برای تحلیل دادهها و پیادهسازی مدلهای «هوش مصنوعی» (Artificial Intelligence) استفاده میکنند. انبار داده بیشتر برای بررسی دادهها توسط متخصصان کسب و کار کاربرد دارد تا بر اساس اطلاعات حاصل شده از آنها، تصمیمات مختلفی در سازمان گرفته شود.
- فضای حافظه: در دریاچه داده از حافظه با قیمت پایین استفاده میشود در حالی که حافظه به کار رفته در انبار داده گران قیمت است و با سرعت بالایی میتوان با آن کار کرد.
- سطح امنیت: در Data Lake از سطح امنیتی کمتری نسبت به انبار داده استفاده میشود.
مزایای دریاچه داده
مزایای مختلفی را میتوان برای Data Lake برشمرد که در ادامه به برخی از مهمترین آنها اشاره میکنیم:
- از آن جایی که برای ذخیره کردن دادههای استخراج شده از منابع مختلف درون دریاچه داده، شمای خاصی در نظر گرفته نمیشود، سرعت ثبت دادهها بالا است.
- در دریاچه داده، دادهها با ساختارهای مختلفی ذخیره میشوند که قابلیت انعطافپذیری تحلیل داده را در مقایسه با انبار داده بیشتر میکند.
- از دادههای دریاچه داده میتوان به راحتی برای الگوریتم های یادگیری ماشین و مدلهای هوش مصنوعی استفاده کرد و از آنها برای ساخت مدلهای پیشبینی کننده بهره برد.
- دسترسی وسیع کاربران به دریاچه داده از دیگر مزیتهای آن محسوب میشود و افراد در سطح سازمان میتوانند به Data Lake دسترسی داشته باشند.
- با استفاده از Data Lake میتوان تحلیلهای مختلفی بر روی دادهها انجام داد.
- مقیاسپذیری با هزینه مالی مناسب از دیگر نکات مثبت Data Lake محسوب میشود.
- در هنگام کار با Data Lake به راحتی میتوان تغییرات مختلفی را بر روی دادهها اعمال کرد.
- کاربران مختلف سازمان میتوانند به Data Lake دسترسی داشته باشند.
چالش های دریاچه داده چیست؟
در زمان طراحی و ساخت Data Lake به این نکته توجه داشته باشیم که برنامهریزی و مدیریت نادرست میتواند دریاچه داده را به «باتلاق داده» (Data Swamp) تبدیل کند.
باتلاق داده، دریاچه دادهای است که به دلیل طراحی اشتباه، وجود دادههای قدیمی، کاربران ناآگاه و عدم استفاده طولانی مدت از آن، دیگر ارزش استفاده ندارد. بنابراین، کسب و کارها باید در زمان طراحی دریاچه داده چالشهای آن را مد نظر قرار دهند که بدین منظور میتوان اقدامات زیر را انجام داد:
- تعیین اولویتهای کسب و کار: سازمانها باید اولویتهایی برای جمعآوری داده در نظر بگیرند تا دادههای مورد نیاز و باکیفیت را در دریاچه داده ذخیره کنند. جمعآوری دادههای نامربوط و ناصحیح برای دریاچه داده، بر روی تحلیل داده و تصمیمگیریهای مبتنی بر داده تاثیر منفی خواهد گذاشت.
- تعیین موارد استفاده از دادهها و مشخص کردن کاربران نهایی: کاربرد دادههایی که در دریاچه داده ذخیره میشوند، باید به طور دقیق مشخص باشند. همچنین، دادهها باید بر اساس دانش و مهارت کاربران جهت تجزیه و تحلیل آنها تهیه شوند.
- حفظ ارتباط موثر با کاربران: هدف دریاچه داده برای نگهداری دادهها باید مشخص باشد. پیش از پیادهسازی Data Lake کسب و کارها باید از این موضوع مطمئن شوند که کاربران نحوه استفاده از Data Lake و دلیل کاربرد آن را به خوبی میدانند. باید مستنداتی برای دریاچه داده تهیه شود و کاربران با کمک این مستندات به اطلاعات دقیق دادهها اشراف داشته باشند.

مفاهیم اصلی دریاچه داده
در این بخش، به توضیح مفاهیم اصلی Data Lake میپردازیم که برای درک معماری و ساختار آن لازم هستند. در ادامه، فهرستی از عناوین مهم Data Lake ذکر شدهاند:
- «دریافت داده» (Data Ingestion)
- «فضای ذخیرهسازی داده» (Data Storage)
- «نظارت داده» (Data Governance)
- امنیت Data Lake
- کیفیت داده
- «مکاشفه داده» (Data Discovery)
- «بازرسی داده» (Data Auditing)
- «منشا داده» (Data Lineage)
- «بازیابی داده» (Data Exploration)
در بخش بعدی مطلب حاضر از مجله فرادرس، به توضیح مختصری پیرامون هر یک از مفاهیم اصلی Data Lake میپردازیم که در درک معماری دریاچه داده کمک کند.
دریافت داده در دریاچه داده
در دریاچه داده بخشی برای دریافت داده از منابع مختلف و بارگذاری آنها درون Data Lake وجود دارد. دادههای دریافتی میتوانند ساختاریافته، غیرساختاریافته و نیمه ساختاریافته باشند و از منابعی نظیر بانک اطلاعاتی، ایمیل، اینترنت اشیا و FTP در قالب چندین دسته یا به صورت بلادرنگ استخراج شوند.
فضای ذخیره سازی داده در دریاچه داده چه خصوصیاتی دارد؟
فضایی که درون Data Lake برای ذخیره دادهها در نظر گرفته شده است، باید مقیاسپذیر باشد تا بتوان هر حجمی از داده را درون آن ذخیره کرد. همچنین، در این فضا باید بتوان به دادهها با فرمتهای مختلف به راحتی و سریع دسترسی داشت و در میان دادهها به جستجو پرداخت.
نظارت داده در Data Lake
نظارت داده در Data Lake شامل روال مدیریت دادهها، نحوه استفاده از آنها، کنترل امنیت و یکپارچهسازی آنها است.
امنیت دریاچه داده
امنیت در هر لایه از Data Lake باید حفظ و سطوح دسترسی کاربران به دریاچه داده باید کنترل شود. همچنین، باید ابزارهای مختلفی را برای دسترسی به دادهها و داشبوردها در نظر بگیرید و امنیت آن را چک کنید.
کیفیت داده های Data Lake
دادههایی که در دریاچه داده ذخیره میشوند، باید از کیفیت خوبی برخوردار باشند و به نیاز سازمان پاسخ دهند. جمعآوری دادههای بیارزش و بیربط باعث میشود اطلاعات صحیحی از تحلیل آنها حاصل نشود. گزارشات نادرست حاصل شده از دادهها منجر به تصمیمگیریهای نادرست مدیران سازمانها و شکست در انجام اهداف خواهد شد.

مکاشفه داده در Data Lake
یکی از مراحل مهمی که پیش از آمادهسازی و تحلیل داده انجام میشود، مرحله مکاشفه داده است. در این گام از روشهای برچسبگذاری داده استفاده میشود تا بتوان دادهها را بهتر درک کرد. همچنین، این مرحله شامل سازماندهی و تفسیر دادههای ذخیره شده در Data Lake است.
بازرسی داده های Data Lake
بازرسی داده شامل بررسی تغییرات اعمال شده بر روی دادههای دریاچه داده است. میتوانید دقیقا مشخص کنید چه فردی در چه زمانی چه تغییراتی را بر روی دادهها اعمال کرده است.
منشا داده در دریاچه داده
در دریاچه داده میتوانید تغییرات اعمال شده بر روی دادهها را در طول زمان بررسی کنید و با مقایسه دادههای تغییر یافته با دادههای اصلی به سادگی خطاهای رخ داده را در روال پردازش داده تشخیص دهید.
بازیابی داده در Data Lake چیست؟
بازیابی داده به عنوان اولین مرحله در پردازش داده محسوب میشود. در این گام، پایگاه داده مورد نظر برای استخراج دادهها مشخص و عملیات بازیابی دادهها آغاز میشود.
معماری Data Lake چیست؟
اجزای اصلی Data Lake شامل دو بخش فضای ذخیرهسازی و بخش محاسباتی است. هر دوی این اجزا را میتوان بر روی سختافزار سازمان یا بر روی فضای ابر پیادهسازی کرد. به عبارتی، سازمانها میتوانند معماری Data Lake را کاملاً بر روی سختافزار سازمان طراحی یا کل آن را بر روی فضای ابر با چندین بستر ابری منتقل کنند.
به منظور پیادهسازی Data Lake میتوان از پلتفرمهای مختلفی استفاده کرد که پرکاربردترین آنها «هادوپ» (Hadoop) و پلتفرمهای ابری نظیر Amazon Web Service ،Microsoft Azure و Google Cloud هستند. در تصویر زیر لایههای معماری Data Lake را ملاحظه میکنید که هر بخش را در ادامه توضیح خواهیم داد:
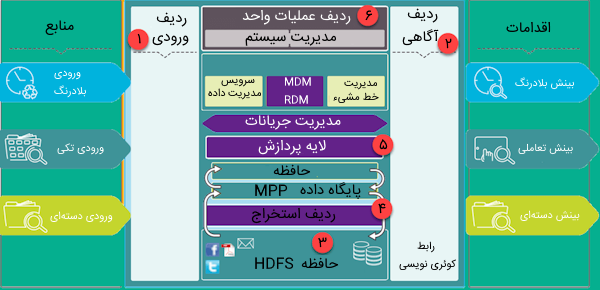
- «ردیف ورودی» (Ingestion Tier): ردیف سمت چپ در تصویر بالا ردیف ورودی Data Lake را نشان میدهد که از طریق این ردیف، دادهها از منابع مختلف به شکل دستهای یا بلادرنگ دریافت میشوند.
- «ردیف آگاهی» (Insights Tier): ردیف سمت راست در تصویر بالا که از طریق آن میتوان در Data Lake جستجو کرد، ردیف آگاهی نام دارد که با کوئریهای SQL و NoSQL و حتی با استفاده از برنامه Excel میتوان در دریاچه داده به جستجو پرداخت.
- بخش HDFS: این بخش برای نگهداری تمام دادههای Data Lake استفاده میشود که مورد استفاده سیستم قرار نمیگیرند.
- «ردیف استخراج» (Distillation Tier): این بخش دادهها را از حافظه استخراج و آنها را برای تحلیل سادهتر به دادههای ساختاریافته تبدیل میکند.
- «ردیف پردازش» (Processing Tier): این بخش مسئول اجرای الگوریتمهای تحلیلی و کوئریهای کاربر به منظور تولید دادههای ساختاریافته برای تحلیل سادهتر است.
- «ردیف عملیات واحد» (Unified Operations Tier): این بخش مدیریت و کنترل سیستم را بر عهده دارد.
نرمافزارهای معماری Data Lake به منظور سازماندهی دادهها و سادهتر کردن دسترسی به آنها استفاده میشوند. در ادامه این بخش، به اجزای نرمافزارهای معماری دریاچه داده و عملکرد آنها میپردازیم.
معماری هادوپ برای دریاچه داده
از سرورهای توزیع شده هادوپ برای ذخیره کلان داده استفاده میشود. در بخش مرکزی این نرمافزار، لایهای با عنوان HDFS وجود دارد که برای ذخیرهسازی و تهیه رونوشت از دادههای سرورها استفاده میشود. YARN مدیر منابع این نرمافزار است که زمانبندی استفاده از منابع هر گره را مشخص میکند. MapReduce ماژولی است که در هادوپ برای تقسیم دادهها به بخشهای کوچکتر و پردازش آنها بر روی سرورها استفاده میشود.
علاوه بر سه بخش اصلی هادوپ که به آن اشاره کردیم، این نرمافزار از ابزارهای Hive ،Pig ،Flume ،Sqoop و Kafka به منظور دریافت، آمادهسازی و استخراج داده استفاده میکند. دریاچه داده هادوپ را میتوان هم بر روی سختافزار سازمان و هم بر روی پلتفرمهای ابری نظیر Cloudera و HortoWorks پیادهسازی کرد. مهمترین مزایای استفاده از Data Lake هادوپ در ادامه ذکر شدهاند:
- هادوپ در حوزه فناوری اطلاعات کاربرد فراوان دارد.
- هادوپ متن باز است و هزینه مالی کمی دارد.
- هادوپ از ابزارهای بسیاری برای ETL پشتیبانی میکند.
- دارای ویژگی مقیاسپذیری است.
معماری AWS برای Data Lake
در معماری AWS بخشی مرکزی با عنوان Amazon S3 وجود دارد که مربوط به ذخیرهسازی و مدیریت کلان دادهها است. همچنین، در این نرمافزار از ابزارهای Kinesis Streams ،Kinesis Firehose ،Snowball و Direct Connect برای دریافت داده و انتقال آنها به بخش S3 استفاده میشود.
به علاوه، در معماری AWS دریاچه داده، یک سرویس انتقال پایگاه داده وجود دارد که از آن میتوان برای انتقال دادههای موجود بر سختافزار سازمان به فضای ابری استفاده کرد. DynamoDB، پایگاه داده No-SQL و Elastic Search در نرمافزار AWS برای فرآیندهای کوئری دریاچه داده کاربرد دارند. بخش Cognito User Pools در این برنامه به منظور احراز هویت کاربران و تعیین سطوح دسترسی آنها استفاده میشود.

سرویسهایی نظیر Security Token Service ،Key Management Service ،CloudWatch و CloudTrail سطح امنیت دریاچه داده را بررسی میکنند. ابزارهای RedShift ،QuickSight و EMR برای پردازش و تحلیل دادههای Data Lake کاربرد دارند. نقاط قوت نرمافزار AWS را در ادامه ملاحظه میکنید:
- امنیت بالای برنامه
- هزینه پایین
- جداسازی بخشهای محاسبات و ذخیرهسازی Data Lake (این ویژگی سبب میشود بتوان به راحتی ویژگی مقیاسپذیری هر بخش را افزایش داد)
- داشتن ویژگیها و ابزارهای قوی و جامع
معماری Azure برای دریاچه داده
برنامه Azure توسط شرکت مایکروسافت ارائه شد. معماری Azure شامل یک لایه برای ذخیرهسازی داده و یک لایه برای تحلیل آنها است که دو بخش Azure Data Lake Analytics و HDInsight دارد.
لایه ذخیرهسازی Azure بر اساس استاندارد HDFS طراحی شده است و حافظه نامحدودی برای ذخیره دادهها دارد. در این فضای حافظه میتوان هر حجم از داده با فرمتهای متفاوت را ذخیره کرد. با استفاده از Azure میتوان به راحتی دادههای ذخیره شده بر روی سختافزار سازمان را به فضای ابری منتقل کرد. HDInsight یک سرویس تحلیل دریاچه داده ابری است که اجازه میدهد با استفاده از ابزارهایی نظیر Spark ،Hive ،Kafka و Storm بتوان به دادهها دسترسی داشت.
بخش Azure Data Lake Analytics نیز برای تحلیل داده به کار میرود اما رویکرد آن با HDInsight متفاوت است. این بخش به جای استفاده از ابزارهایی مانند Hive، از یک زبان با نام U-SQL به منظور دسترسی به دادهها پشتیبانی میکند. این زبان، ترکیبی از زبانهای برنامه نویسی SQL و C# است. از این بخش میتوان برای پردازش کلان داده با سرعت بالا و هزینه پایین استفاده کرد.
ساخت Data Lake مناسب
در این بخش از مطلب حاضر، به این پرسش پاسخ میدهیم که برای داشتن یک دریاچه داده مناسب به چه مواردی باید توجه داشته باشیم؟ همسویی Data lake با استراتژیهای تجاری سازمانها و شرکتها و داشتن حمایت اجرایی از موارد مهمی است که باید در هنگام ساخت دریاچه داده مد نظر قرار گرفته شوند. علاوهبراین، بر اساس تجربیات دهها شرکتی که از دریاچه داده نتایج موفقیتآمیز کسب کردهاند میتوان به سه پیشنیاز کلیدی برای داشتن یک Data Lake موفق اشاره کرد:
- انتخاب پلتفرم مناسب برای Data Lake
- جمعآوری دادههای صحیح و مناسب برای Data Lake
- انتخاب رابط مناسب برای Data Lake

در ادامه، به توضیح هر یک از موارد ذکر شده در بالا میپردازیم.
انتخاب بهترین پلتفرم برای Data Lake
فناوریهای کلان داده نظیر هادوپ و ابزارهای مبتنیبر ابر مانند Amazon Web Service ،Microsoft Azure و Google Cloud Platform پلتفرمهای رایج برای پیادهسازی Data Lake هستند. این فناوریها ویژگیهای مهمی دارند که در ادامه به آنها پرداخته شده است:
- حجم: این پلتفرمها به گونهای طراحی شدهاند که مقیاسپذیر هستند و با افزایش حجم، خللی در عملکرد آنها ایجاد نمیشود.
- هزینه: برای نگهداری دادههایی با حجم کم از حافظههایی مانند هارد دیسک استفاده میشود که هزینه زیادی ندارد. اما برای کار با کلان داده و پردازش آنها به حافظههای بیشتری احتیاج است که تهیه چنین حافظههایی هزینههای مالی زیادی را دربر دارد. پلتفرمهایی که برای Data Lake استفاده میشوند، میتوانند فضای نامحدودی را برای نگهداری دادهها با هزینه پایین برای کاربران فراهم کنند.
- تنوع: در پایگاه دادههای رابطهای صرفاً میتوان دادههای ساختاریافته ذخیره کرد. اما پلتفرمهای Data Lake این امکان را فراهم میکنند تا بتوان دادهها را با انواع مختلف فرمت در دریاچه داده ذخیره کرد.
- تضمین ماندگاری در آینده: نیازهای سازمانها در گذر زمان تغییر میکنند و به همین خاطر باید اطمینان حاصل کنیم دادههای جمعآوری شده برای Data Lake را میتوان در سالهای آتی نیز به کار برد. اگر برای ذخیرهسازی دادهها از پایگاه دادههای رابطهای استفاده شود، به منظور دسترسی به آنها فقط باید از همین پایگاه دادهها استفاده کنیم. از سوی دیگر، پلتفرمهای کلان داده این امکان را فراهم میکنند تا با هر برنامه و ابزار پردازشگری بتوان به دادهها دسترسی داشت.
جمعآوری دادههای صحیح و مناسب برای دریاچه داده
از دریاچه داده به منظور ذخیرهسازی دادهها با فرمت اولیه آنها استفاده میشود. دادهها بر اساس نیاز افراد سازمان باید در فرمت مناسب در بیایند و عملیات پردازش بر روی آنها اعمال شود. بنابراین، لازم نیست پیش از ذخیرهسازی دادهها در Data Lake پیش پردازشی برای آنها انجام دهیم. این امر سبب میشود در کاهش زمان پردازش صرفهجویی و تمرکز بر روی استخراج دادههای بیشتر از منابع مختلف سوق داده شود تا در آینده دادهها برای اهداف مختلف به کار گرفته شوند.
میتوان از یک مثال ملموس از دنیای واقعی برای درک این موضوع استفاده کرد. فرض کنید قلکی دارید که در آن پولهای مختلف کشورهای سراسر دنیا را میاندازید. پس از پر شدن قلک، تصمیم میگیرید به کشوری سفر کنید و از پولهای جمع شده درون قلک برای سفر خود استفاده کنید. بدین ترتیب، در کشور مقصد، تمامی پولهای قلک خود را به پول رایج کشور مقصد تبدیل میکنید. قلک را میتوان به عنوان Data Lake تلقی کرد و پولهای درون آن را به مثابه دادههای دریاچه داده دانست که هر زمان نیاز بود، آن را به اطلاعات ارزشمند تبدیل میکنید.
انتخاب رابط مناسب برای Data Lake
پس از جمعآوری دادهها و ذخیره آنها در Data Lake باید برای دسترسی کاربران به دادهها جنبههای کاربردی مختلفی را در نظر بگیریم. به عنوان مثال، تحلیلگران داده نیاز دارند که با دادههای پردازش شده کار کنند تا اطلاعات ارزشمندی از آنها استخراج و گزارشاتی را بر اساس آنها تهیه کنند که به مدیران سازمان در تصمیمگیریهای مهم کمک شایانی میکنند.
از سوی دیگر، دانشمندان داده نیاز دارند تا با دادههای خام کار کنند و از آنها برای آموزش مدلهای هوش مصنوعی بهره بگیرند. بنابراین، این افراد از دادههای پردازش شده Data Lake نمیتوانند استفاده کنند. بنابراین، نیازمندیهای کاربران Data Lake را باید شناسایی کرد تا بر اساس آنها، مناسبترین رابط کاربری برای کار با دریاچه داده طراحی شود.
بهترین بستر برای پیاده سازی دریاچه داده کدام است؟
استفاده از سختافزارهای سازمان برای پیادهسازی دریاچه داده یک روش قدیمی است که بدین منظور از هادوپ استفاده میشود. هادوپ مقیاسپذیر است و هزینه مالی پایینی دارد و دارای عملکرد خوبی برای کار با دادههای محلی (دادهها بر روی سختافزار سازمان ذخیره شده باشند) است. با این حال، چالشهایی برای طراحی زیرساخت هادوپ وجود دارد که در ادامه به آنها میپردازیم:
- اشغال بخش عظیمی از فضای سرور و افزایش هزینههای مالی
- زمانبر بودن راهاندازی سختافزارها و مراکز داده مورد نیاز
- زمانبر بودن و هزینهبر بودن تغییر ویژگی مقیاسپذیری دریاچه داده هادوپ

Data Lake ابری چالشهای ذکر شده در فهرست بالا را ندارند. به عبارتی، دریاچه دادههای ابری را میتوان به سرعت پیادهسازی کرد و به راحتی میتوان بر اساس نیاز، ویژگی مقیاسپذیری آنها را تغییر داد که همین در کاهش هزینههای مالی و زمانی نقش چشمگیری دارد. البته، استفاده از Data Lakeهای ابری دارای چالشهای مهمی است که در ادامه به آنها اشاره میکنیم:
- برخی از سازمانها به دلیل مسائل امنیتی و حفظ اطلاعات محرمانه و حساس سازمان ترجیح میدهند از بستر ابری برای Data Lake استفاده نکنند.
- برخی از سازمانها از انبار داده برای ذخیره کردن دادههای ساختاریافته خود استفاده میکنند. ممکن است این سازمانها تصمیم بگیرند از بخش محاسبات واحدی برای دسترسی به دادههای ساختاریافته انبار داده و دادههای غیرساختاریافته فضای ابری استفاده کنند که این فرآیند دشوار است.
جمعبندی
نگهداری دادهها و پردازش آنها به عنوان یکی از مهمترین چالشهای سازمانها و شرکتها محسوب میشوند. فناوریهای مختلفی برای کار با داده و مدیریت آنها وجود دارد که یکی از آنها دریاچه داده است. با استفاده از Data Lake میتوان حجم زیادی از دادهها را با فرمت اولیهشان در حافظه نگهداری کنیم و برای تصمیمات مهم از اطلاعات ارزشمند آنها بهره بگیریم. در این مطلب از مجله فرادرس به توضیح مفهوم دریاچه داده پرداختیم و مفاهیم کلیدی، ویژگیها و چالشهای آن را شرح دادیم و به تفاوت آن با سایر مخازن داده اشاره کردیم.
source